前端学HTTP之报文起始行
如果说HTTP是因特网的信使,那么HTTP报文就是它用来搬东西的包裹了。HTTP报文是在HTTP应用程序之间发送的简单的格式化数据块,每条报文都包含一条来自客户端的请求,或者一条来自服务器的响应。它们由三个部分组成:由起始行、首部和实体的主体部分。本文将主要介绍HTTP报文起始行

报文语法
所有的HTTP报文都可以分为两类:请求报文(request message)和响应报文(response message)。请求报文会向Web服务器请求一个动作,响应报文会将请求的结果返回给客户端。请求和响应报文的基本报文结构相同
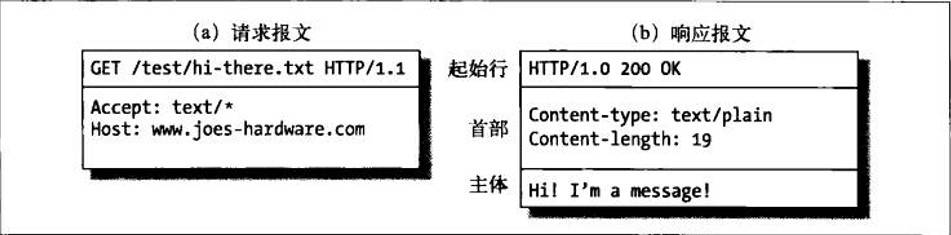
请求报文的格式:
<method> <request-URL> <version> <headers> <entity-body>
响应报文的格式:
<version><status><reason-phrase> <headers> <entity-body>
【方法(method)】
客户端希望服务器对资源执行的动作。是一个单独的词,比如GET、HEAD或POST
【请求 URL(request-URL)】
命名了所请求资源,或者URL路径组件的完整URL
【版本(version)】
报文所使用的HTTP版本,格式如下:
HTTP/<major>.<minor>
其中主要版本号(major)和次要版本号(minor)都是整数
【状态码(status-code)】
这三位数字描述了请求过程中所发生的情况。每个状态码的第一位数字都用于描述状态的一般类别(“成功”、“出错”等)
【原因短语(reason-phrase)】
数字状态码的可读版本,包含行终止序列之前的所有文本
【首部(header)】
可以有零个或多个首部,毎个首部都包含一个名字,后面跟着一个冒号(:),然后是一个可选的空格,接着是一个值,最后是一个CRLF。首部是由一个空行(CRLF)结束的,表示了首部列表的结束和实体主体部分的开始
【实体的主体部分(entity-body)】
实体的主体部分包含一个由任意数据组成的数据块。并不是所有的报文都包含实体的主体部分,有时,报文只是以一个CRLF结束
分类
所有的HTTP报文都以一个起始行作为开始。请求报文的起始行说明了要做些什么,响应报文的起始行说明发生了什么。下面将详细介绍起始行的内容
请求行
请求报文请求服务器对资源进行一些操作。请求报文的起始行,或称为请求行,包含了一个方法和一个请求URL,这个方法描述了服务器应该执行的操作,请求URL描述了要对哪个资源执行这个方法。请求行中还包含HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP。所有这些字段都由空格符分隔
响应行
响应报文承载了状态信息和操作产生的所有结果数据,将其返回给客户端。响应报文的起始行,或称为响应行,包含了响应报文使用的HTTP版本、数字状态码,以及描述操作状态的文本形式的原因短语。所有这些字段都由空格符进行分隔
方法
请求的起始行以方法作为开始,方法用来告知服务器要做些什么
HTTP常用方法共以下8种
GET:获取资源 POST:传输实体主体 PUT:传输文件 HEAD:获取报文首部 DELETE:删除文件 OPTIONS:询问支持的方法 TRACE:追踪路径 CONNECT:要求用隧道协议连接代理
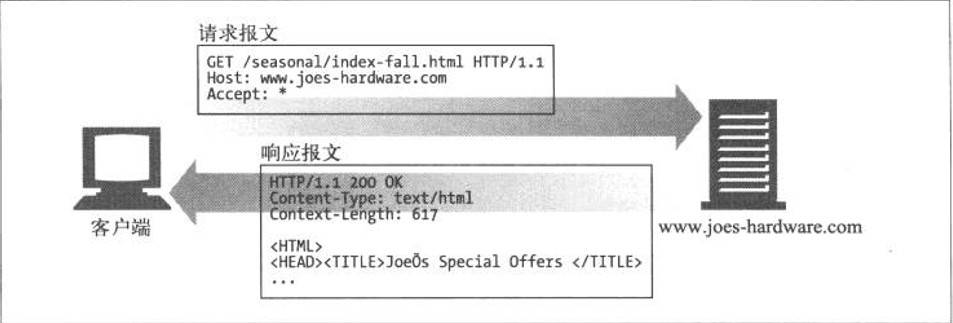
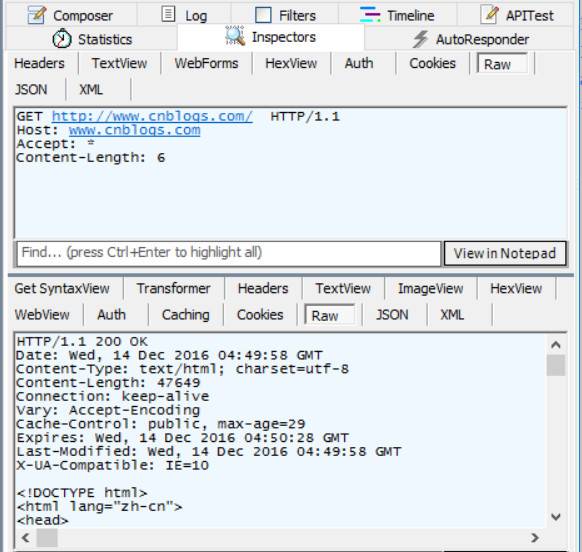
GET
GET是最常用的方法。通常用于请求服务器发送某个资源
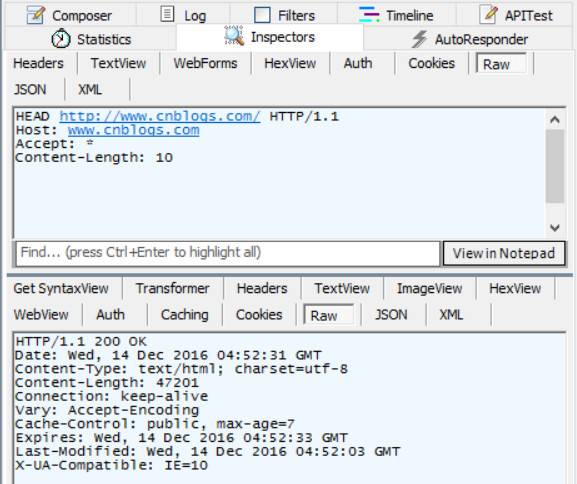
HEAD
HEAD方法与GET方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检査。使用HEAD,可以:1、在不获取资源的情况下了解资源的情况(比如,判断其类型);2、通过査看响应中的状态码,看看某个对象是否存在;3、通过査看首部,测试资源是否被修改

PUT
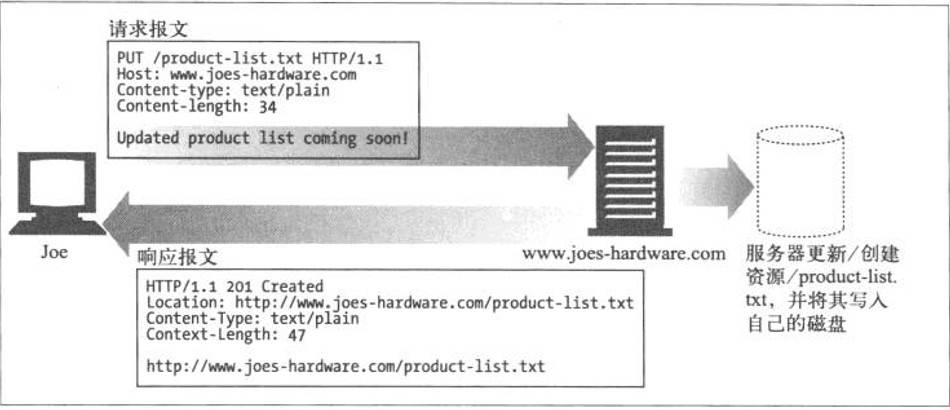
与GET从服务器读取文档相反,PUT方法会向服务器写入文档。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置
但是,由于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不使用该方法。若配合Web应用程序的验证机制,或架构设计采用REST(REpresentational State Transfer,表征状态转移)标准的同类Web网站,就可能会开放使用PUT方法
POST
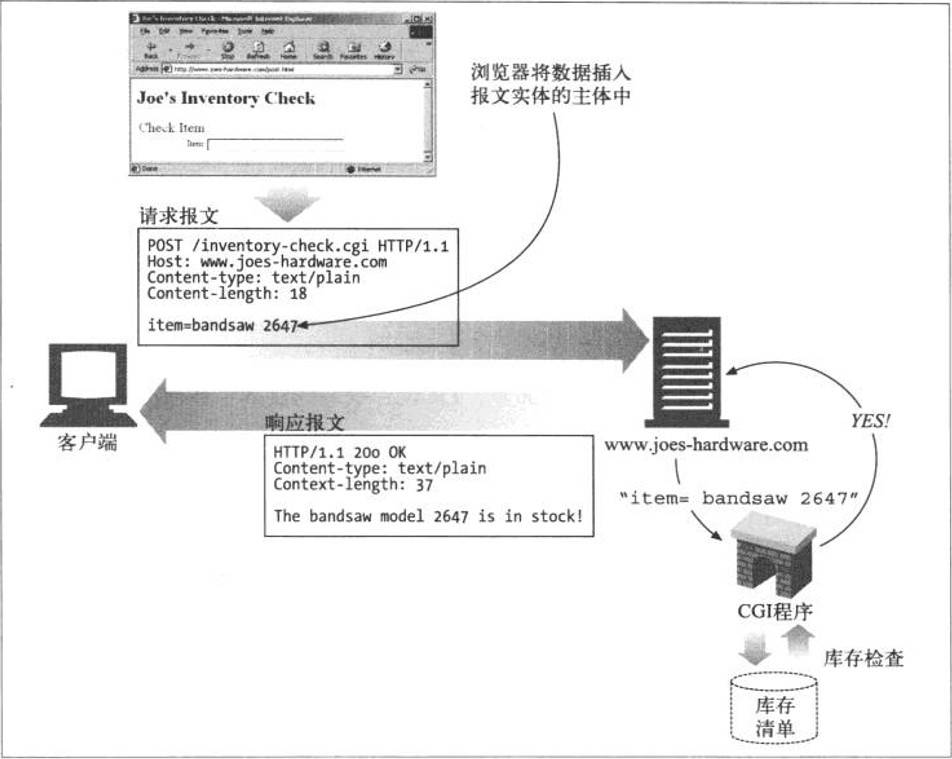
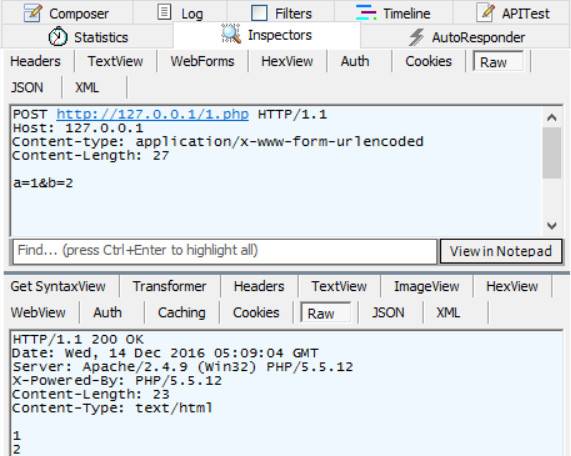
POST方法起初是用来向服务器输入数据的。实际上,通常会用它来支持HTML的表单
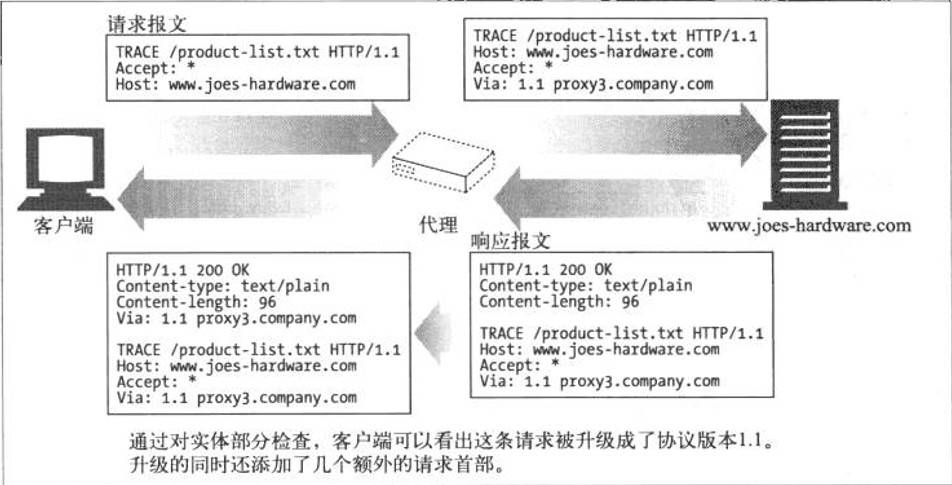
TRACE
TRACE请求会在目的服务器端发起一个“环回”诊断。行程最后一站的服务器会弹回一条TRACE响应,并在响应主体中携带它收到的原始请求报文。这样客户端就可以査看在所有中间HTTP应用程序组成的请求/响应链上,原始报文是否,以及如何被毁坏或修改过
发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减 1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码 200 OK 的响应
但是,TRACE方法本来就不怎么常用,再加上它容易引发XST(Cross-Site Tracing,跨站追踪)攻击,通常就更不会用到了
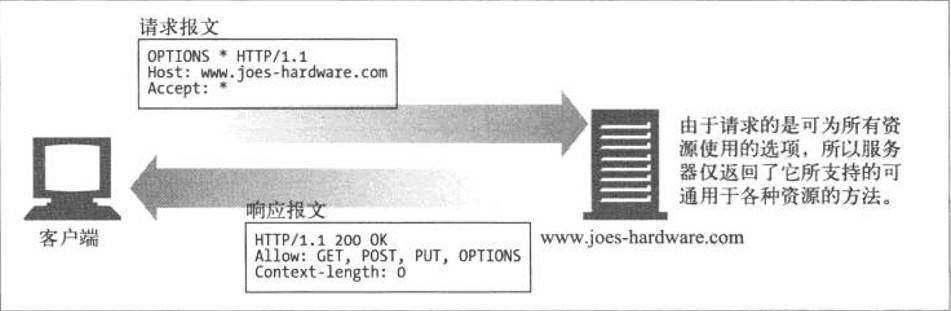
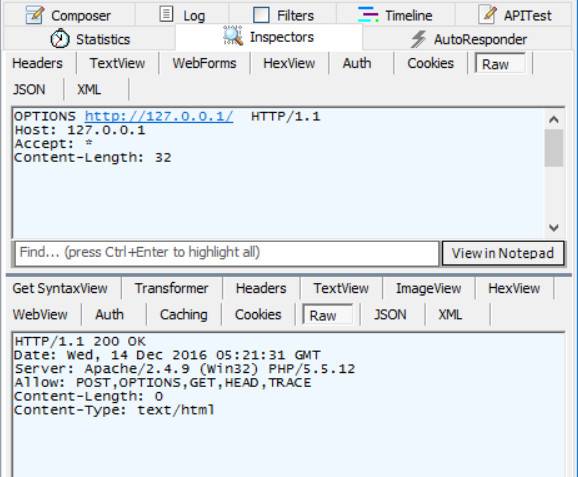
OPTIONS
OPTIONS方法请求Web服务器告知其支持的各种功能。可以询问服务器通常支持哪些方法,或者对某些特殊资源支持哪些方法
这为客户端应用程序提供了一种手段,使其不用实际访问那些资源就能判定访问各种资源的最优方式
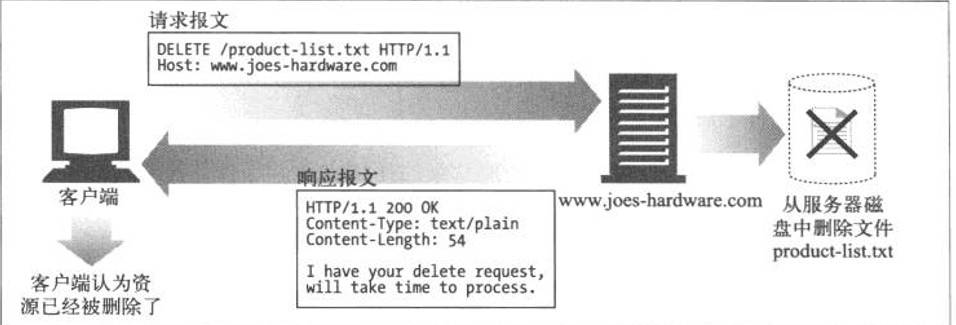
DELETE
DELETE方法所做的事情就是请服务器删除请求URL所指定的资源
但是,HTTP/1.1 的 DELETE 方法本身和 PUT 方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法。当配合Web应用程序的验证机制,或遵守REST标准时还是有可能会开放使用的
CONNECT
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL(Secure Sockets Layer,安全套接层)和TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输
扩展方法
HTTP被设计成字段可扩展的,这样新的特性就不会使老的软件失效了。扩展方法指的就是没有在HTTP/1.1规范中定义的方法。服务器会为它所管理的资源实现一些HTTP服务,这些方法为开发者提供了一种扩展这些HTTP服务能力的手段。下面表中列出的这些方法是WebDAV HTTP扩展包含的所有方法,这些方法有助于通过HTTP将Web内容发布到Web服务器上去

版本
HTTP协议有几个版本,HTTP应用程序要尽量强健地处理各种不同的HTTP协议变体
【HTTP/0.9】
HTTP的1991原型版本称为HTTP/0.9。这个协议有很多严重的设计缺陷,只应该用于与老客户端的交互。HTTP/0.9只支持GET方法,不支持多媒体内容的MIME类型、各种HTTP首部,或者版本号。HTTP/0.9定义的初衷是为了获取简单的HTML对象,它很快就被H1TP/1.0取代了
【HTTP/1.0】
1.0是第一个得到广泛使用的HTTP版本。HTTP/1.0添加了版本号、各种HTTP首部、一些额外的方法,以及对多媒体对象的处理,HTTP/1.0使得包含生动图片的Web页面和交互式表格成为可能,而这些页面和表格促使万维网为人们广泛地接受。这个规范从未得到良好地说明。在这个HTTP协议的商业演进和学术研究都在快速进行的时代,它集合了一系列的最佳实践
【HTTP/1.0】
在20世纪90年代中叶,很多流行的Web客户端和服务器都在飞快地向HTTP中添加各种特性,以满足快速扩张且在商业上十分成功的万维网的需要。其中很多特性,包括持久的keep-alive连接,虚拟主机支持,以及代理连接支持都被加入到HTTP之中,并成为非官方的事实标准。这种非正式的HTTP扩展版本通常称为 HTTP/1.0+
【HTTP/1.1】
HTTP/1.1重点关注的是校正HTTP设计中的结构性缺陷,明确语义,引入重要的性能优化措施,并删除一些不好的特性。HTTP/1.1还包含了对更复杂的Web应用程序和部署方式的支持。HTTP/1.1是当前使用的HTTP版本
【HTTP-NG(又名HTTP/2.0)】
HTTP-NG是HTTP/1.1后继结构的原型建议,它重点关注的是性能的大幅优化,以及更强大的服务逻辑远程执行框架。在与HTTP/1.1完全语义兼容的基础上,进一步减少了网络延迟
随着2015年5月14日HTTP/2协议正式版的发布,越来越多的网站和第三方CDN服务开始启用HTTP/2。HTTP/2是新一代的 HTTP,也是HTTP的未来
状态码
HTTP状态码负责表示客户端HTTP请求的返回结果、标记服务器端的处理是否正常、通知出现的错误等工作。HTTP状态码被分成了五大类,不同的类型代表不同类别的状态码
1XX Informational(信息性状态码) 表示接收的请求正在处理 2XX Success(成功状态码) 表示请求正常处理完毕 3XX Redirection(重定向状态码) 表示需要进行附加操作以完成请求 4XX Client Error(客户端错误状态码) 表示服务器无法处理请求 5XX Server Error(服务器错误状态码) 表示服务器处理请求出错
只要遵守状态码类别的定义,即使改变RFC2616中定义的状态码,或服务器端自行创建状态码都没问题
仅记录在RFC2616上的HTTP状态码就达40种,若再加上WebDAV(Web-based Distributed Authoring and Versioning,基于万维网的分布式创作和版本控制)(RFC4918、5842)和附加HTTP状态码(RFC6585)等扩展,数量就达60余种。但实际上经常使用的大概只有十几种
【1XX】
【2XX】
客户端发起请求时,这些请求通常是成功的。服务器有一组用来表示成功的状态码,分别对应不同类型的请求
【3XX】
重定向状态码要么告知客户端使用替代位置来访问他们所感兴趣的资源,要么就提供一个替代的响应而不是资源的内容。如果资源已被移动,可发送一个重定向状态码和一个可选的Location首部来告知客户端资源已被移走,以及现在可以在哪里找到它。这样,浏览器就可以在不打扰使用者的情况下,透明地转入新的位置了
【4XX】
有时客户端会发送一些服务器无法处理的东西,比如格式错误的请求报文,或者请求一个不存在的URL
浏览网页时,我们都看到过404 Not Found错误码——这只是服务器在告诉我们,它对我们请求的资源一无所知。很多客户端错误都是由浏览器来处理的。只有少量错误,比如404,还是会穿过浏览器来到用户面前
【5XX】
有时客户端发送了一条有效请求,服务器自身却出错了。这可能是客户端碰上了服务器的缺陷,或者服务器上的子元素,比如某个网关资源出了错。代理尝试着代表客户端与服务器进行交流时,经常会出现问题。代理会发布5XX服务器错误状态码来描述所遇到的问题